
API利用料だけ計算していませんか? PoCから本番運用へ進むための「お金」の話
生成AIの技術検証(PoC)が無事に終わり、いざ全社展開や本番運用へフェーズを進めようとした時、多くのプロジェクトが**「見積もり」**という壁に衝突します。
「全社員が使ったら、月額いくらになるのか?」 「アクセスが集中した時、クラウド破産しないか?」
経営層からのこうした問いに対し、「やってみないとわかりません」では稟議は通りません。しかし、従来のITシステムのような「サーバー代+ライセンス費」という固定費モデルと異なり、生成AIは「トークン課金+コンピュート課金」という完全従量モデルが基本です。
本記事では、複雑なAIデータ基盤のコスト構造を分解し、スモールスタートでリスクを抑えつつ、将来的なスケールを見据えた「失敗しないコスト試算」のポイントを主要プラットフォーム(Azure, AWS, GCP, Snowflake, Databricks)の比較を交えて解説します。
1. 「氷山の一角」しか見ていない? AI基盤のコスト構造
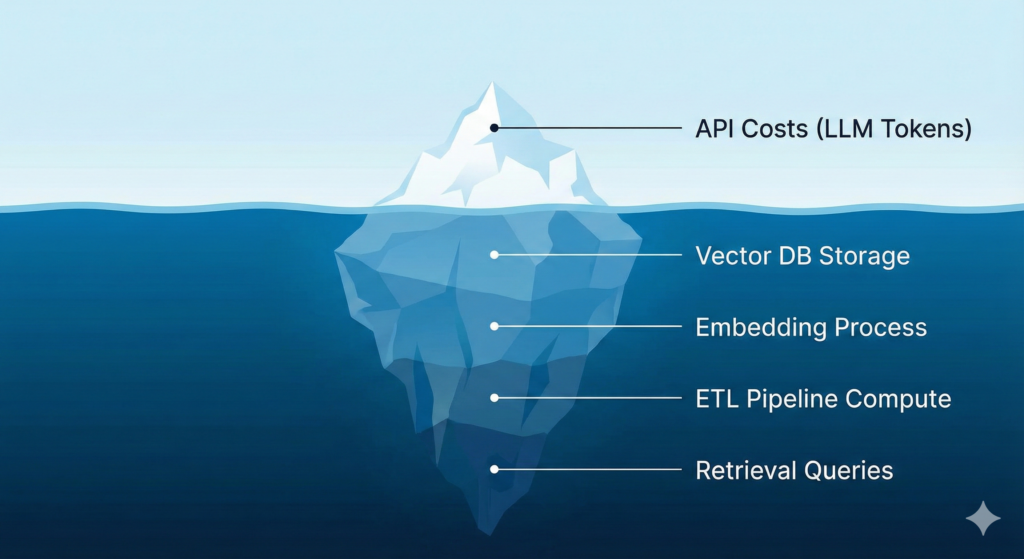
AIプロジェクトの予算計画で最も多い失敗は、「LLMのAPI利用料(トークン単価)」だけで計算してしまうことです。
確かに GPT-4o などのモデル利用料はコストの主役ですが、それは氷山の一角に過ぎません。特に、社内データを回答に使わせる「RAG(検索拡張生成)」構成の場合、水面下には以下のようなコストが潜んでいます。
RAG構成における「隠れたコスト」
- ベクトル化(Embedding)コスト
- 社内マニュアルやドキュメントをAIが理解できる数値(ベクトル)に変換する処理です。初期構築時だけでなく、ドキュメントが更新・追加されるたびに発生します。
- ベクトルデータベース(Vector DB)のコスト
- ベクトルデータは通常のテキストデータよりもサイズが大きく、高速な検索のためにメモリ(RAM)を大量に消費します。そのため、一般的なデータベースよりもストレージ単価が高くなる傾向があります。
- ETL/パイプライン処理コスト
- PDFやExcelなどの非構造化データを読み込み、前処理を行うコンピュートリソース費用です。
- 検索クエリのコスト
- ユーザーが質問をするたびに、まず「検索(Retrieve)」が行われ、その後に「生成(Generate)」が行われます。「検索」の段階でも課金されるサービスが多い点を見落としてはいけません。
2. 主要プラットフォーム別:課金体系の「クセ」と注意点
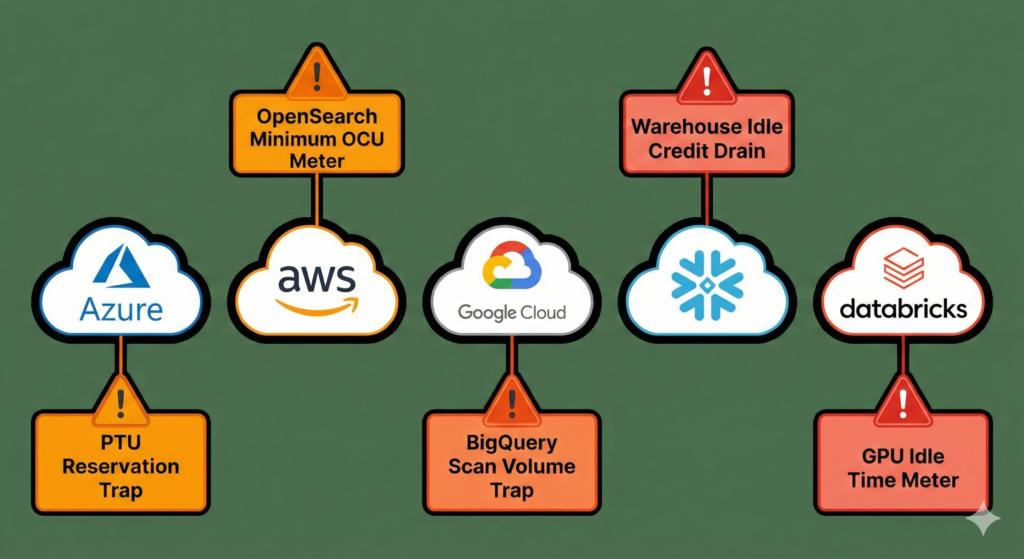
コスト試算を難しくしているのが、クラウドベンダーごとに異なる課金体系です。「従量課金だから安心」と思っていると、思わぬ「最低料金(Minimum Charge)」や「オプション費用」が発生することがあります。
主要5大プラットフォームの特徴と、コスト面での注意点を整理しました。
Azure (Azure OpenAI Service / AI Search)
企業の生成AI基盤として第一選択肢になりやすいAzureですが、検索サービスに注意が必要です。
- ここが落とし穴: RAGの肝となる検索サービス「Azure AI Search」で、精度を高めるために「セマンティック・ランカー」等の機能をONにすると、クエリ単位等での追加課金が発生し、想定よりも高額になるケースがあります。
- スケーリングの壁: 本番運用で安定したレスポンス速度(スループット)を保証しようとすると、「PTU(プロビジョニング スループット ユニット)」という予約型の契約が必要になる場合がありますが、これは比較的高額かつ期間コミットが必要なため、スモールスタートのハードルになります。
AWS (Amazon Bedrock / OpenSearch Serverless)
豊富なモデル(Claude, Titan等)をAPI感覚で切り替えられるBedrockは魅力ですが、DB側に「待機コスト」の概念があります。
- ここが落とし穴: ベクトル検索に「OpenSearch Serverless」を採用する場合、OCU(OpenSearch Compute Unit) という単位で課金されます。これはデータ量が極端に少なくても、インデックスと検索のために最低限のユニット(合計4 OCUなど)を確保する必要があるため、利用者が少ない夜間でもコストが発生し続けます。
- 超小規模には不向き: 月額数万円レベルの超スモールスタートの場合、この「最低OCUコスト」が割高に感じられる可能性があります。
Google Cloud (Vertex AI / BigQuery)
データ分析基盤としてBigQueryを使っている企業には強力な選択肢です。
- ここが落とし穴: BigQueryのベクトル検索機能は便利ですが、BigQuery自体が「スキャンしたデータ量」で課金されるモデルです。インデックス設計を誤ると、検索のたびに大量のデータをスキャンし、クエリコストが跳ね上がるリスクがあります。
- 常時稼働コスト: Vertex AI Vector Search(旧Matching Engine)を独立して立てる場合は、ノードの常時稼働コストがかかるため、利用頻度が低い場合はコストパフォーマンスが悪化します。
Snowflake (Cortex)
データクラウド内でAI機能が完結するSaaS型モデルです。
- 特徴: 「クレジット」消費モデルです。最大のメリットは、データを外部に出さないためセキュリティリスクが低く、管理工数を含めたTCO(総保有コスト)が抑えられる点です。
- 注意点: 計算リソース(ウェアハウス)のサイズ設定がカギです。AI処理が終わった後にウェアハウスを即座に停止する設定にしておかないと、アイドルタイム(待機時間)にもクレジットを消費し続けてしまいます。
Databricks (Mosaic AI)
エンジニアリング要素が強いですが、GPUリソースを細かく制御できます。
- 特徴: Llama 3などのオープンソースモデルを自社環境でホスティング(Model Serving)する場合、トークン課金ではなく「GPUインスタンスの稼働時間」がコストになります。
- 注意点: 毎秒大量のリクエストが来るような大規模運用では、API利用料よりも圧倒的に安くなります。逆に、1時間に数回しか使われないようなケースでは、GPUを空転させている時間が無駄になり、API利用の方が安くなる場合があります。
3. 失敗しない「スモールスタート」の定義とロードマップ
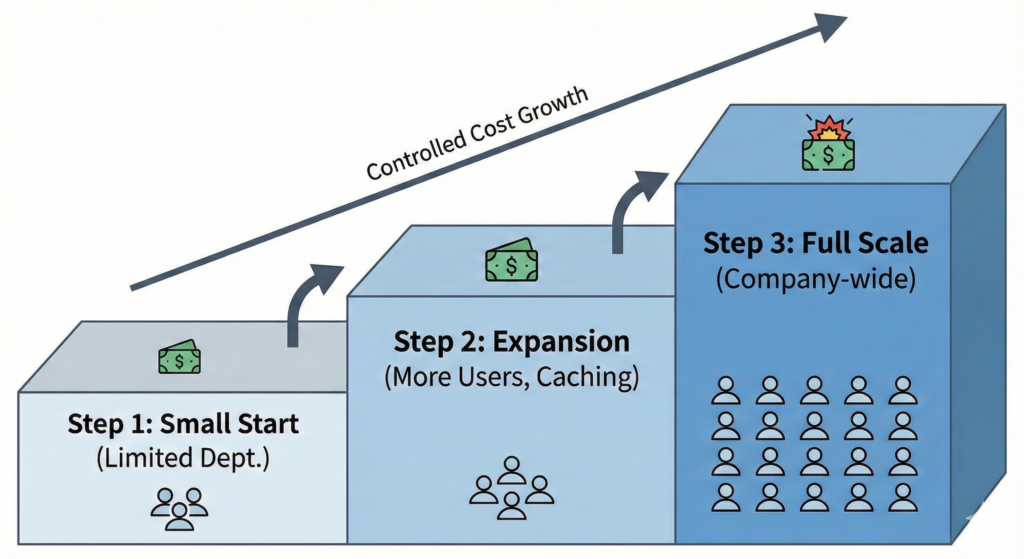
「従量課金が怖いなら、予算の上限を決めればいい」と考えがちですが、AIは業務フローに組み込まれるため、予算オーバーで突然停止すると業務が止まります。
失敗しないためには、以下のステップで**「範囲を限定した本番運用」**を行うことを推奨します。
Step 1. 全社一斉展開を避ける
最初から全社員(例:1,000人)対象の試算をすると、月額数百万〜数千万円という数字が出てしまい、経営層がリスクを恐れてプロジェクトを凍結してしまいます。まずは「法務部の契約書チェック(20名)」や「カスタマーサポートの回答補助(10名)」など、効果が見えやすく、利用者が限定的な部署から始めましょう。
Step 2. 現実的な係数を設定する
「1人あたり1日何回使うか」を、PoCの結果をもとに設定します。
- 計算式例: [対象人数] × [1日あたりの検索回数] × [1回あたりのトークン数(入力+出力)] × [営業日数]
- ここに、先述した「プラットフォームごとの固定費(DB待機コストなど)」を加算します。
Step 3. キャッシュを活用する
コスト削減の基本技術です。「一度AIが回答した内容」はデータベースに保存しておき、同じ質問が来た場合はAI(API)を呼び出さずに保存済みの回答を表示します。これにより、トークン費用と生成待ち時間をダブルで削減できます。
4. コストをコントロールするためのアーキテクチャ設計
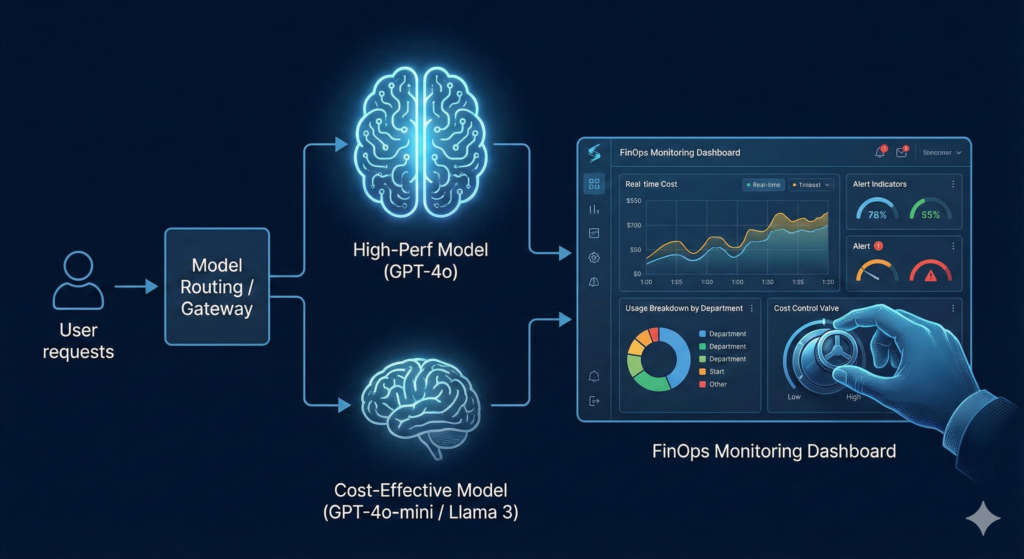
最後に、システム構成(アーキテクチャ)レベルでのコスト対策を紹介します。
- モデルルーティング(Model Routing): すべてのタスクに最高性能の「GPT-4o」や「Claude 3.5 Sonnet」を使う必要はありません。単純な要約や分類タスクには、安価な「GPT-4o-mini」や「Llama 3」などの軽量モデルを使い分ける仕組みを実装します。これにより、品質を維持したままコストを1/10以下に抑えることも可能です。
- FinOps(フィンオプス)の導入 :「月末に請求書を見て驚く」のを防ぐため、日次でコストをモニタリングする仕組みを作ります。「どの部署が」「どの用途で」お金を使っているかを可視化し、異常値を検知したらアラートを出す運用体制(FinOps)を初期段階から設計に組み込みましょう。
AI基盤コストを抑制するアーキテクチャ設計の実践
AI活用のコストを構造的に抑えるには「推論コスト」「学習コスト」「インフラコスト」の3つを分けて設計することが重要だ。推論コストはAPIの選択と呼び出し頻度で決まる。タスクの複雑度に応じてモデルを使い分ける「モデルルーター」の設計が効果的で、定型的な分類タスクには小型・安価なモデル、複雑な推論には大型モデルを使う。インフラコストはスポットインスタンスの活用(AWS/GCPで最大90%割引)とオートスケールの適切な設定で大幅に削減できる。スモールスタートでは「使った分だけ課金のサーバーレス構成」を基本として、最初から固定費のかかるデディケーテッドクラスタを確保しないことがコスト管理の鉄則だ。
スモールスタートからスケールへの移行判断基準
スモールスタートで開始したAIデータ基盤をいつスケールアップするかの判断基準は「ビジネス成果の達成」と「運用限界の到達」の2点で判断する。ビジネス成果として「スモールスタート構成で3ヶ月以内にROIが出た施策があること」がスケール投資の前提となる。運用限界として「クエリのタイムアウトが頻発する」「データ鮮度が要件を満たせない」「エンジニアの手作業対応が週5時間を超える」のいずれかが発生したらスケールのシグナルだ。スケールアップはインフラのサイズ変更だけでなく「より成熟したアーキテクチャへの移行」を意味する場合が多いため、移行計画の立案に1〜2ヶ月の準備期間を見込むことが推奨される。
まとめ:どんぶり勘定は危険。アーキテクチャに基づいた精緻な試算を
AIデータ基盤のコストは、「どのクラウドを選ぶか」と「どう設計するか(アーキテクチャ)」の掛け算で桁が変わります。
「とりあえず使い慣れたAWSで」「話題のAzureで」と安易に決めるのではなく、自社のデータ量、想定ユーザー数、利用頻度に合わせて、SnowflakeやDatabricks、GCPを含めたフラットな視点で比較検討することが、将来的な「クラウド破産」を防ぐ唯一の道です。
貴社のAIプロジェクト、適正コストを把握できていますか? 弊社では、AWS / Azure / GCP / Snowflake / Databricks という主要プラットフォームの特徴を熟知したエンジニアが、お客様の想定ユースケースに基づいた「詳細なコストシミュレーション」と「最適なツール選定」をご支援します。
スモールスタートから全社展開まで、見通しの良いAI導入を実現するために、まずは現状のデータ環境をご相談ください。
よくある質問(FAQ)
Q. AI活用のデータ基盤をスモールスタートするとコストはどのくらいですか?
クラウドDWH(BigQuery Sandbox・Snowflakeフリートライアル)とオープンソースのETLツール(Airbyte)を組み合わせれば月額0〜5万円で始められます。本格移行後の標準構成で月額10〜30万円が中規模企業の目安です。
Q. AI基盤と分析基盤は分けて構築すべきですか?
初期段階では分ける必要はありません。データウェアハウスにデータを集約し、そこからBIツールで分析、MLモデルのfeat ureも同じ基盤から取得する統合設計が運用コストを低く保てます。スケールしてから分離を検討するのが現実的です。
Q. AIコストを抑えるために最も効果的な施策は何ですか?
推論コストの最小化が最も即効性があります。モデルの選択(GPT-4よりGPT-4o-mini等の小型モデルで対応できるタスクの仕分け)とプロンプトキャッシングの活用で、同等品質を維持しながら30〜60%のコスト削減を達成した事例があります。
関連記事:日本企業のLLM活用が遅れる構造的理由と突破口|Mixture of Experts(MoE)アーキテクチャ解説:効率的な大規模モデルの設計思想|クオンツファンドにおけるAI/LLM活用の実態と課題