Amazonの研究チーム(Yu, Chen, Lingら)によって2023年に発表された論文『Temporal Data Meets LLM – Explainable Financial Time Series Forecasting』は、LLMを用いて金融時系列予測と根拠の説明を同時に行うという先駆的な研究です。この研究は、LLMが数値時系列をどのように解釈し、論理的な予測を導き出すかを示す重要なマイルストーンとなりました。
データ設計と時系列のカテゴリ化
本研究ではNASDAQ-100の株価データを対象とし、一般に公開されている日次株価データ、企業プロファイル(メタデータ)、および歴史的な経済・金融ニュースを活用しています。
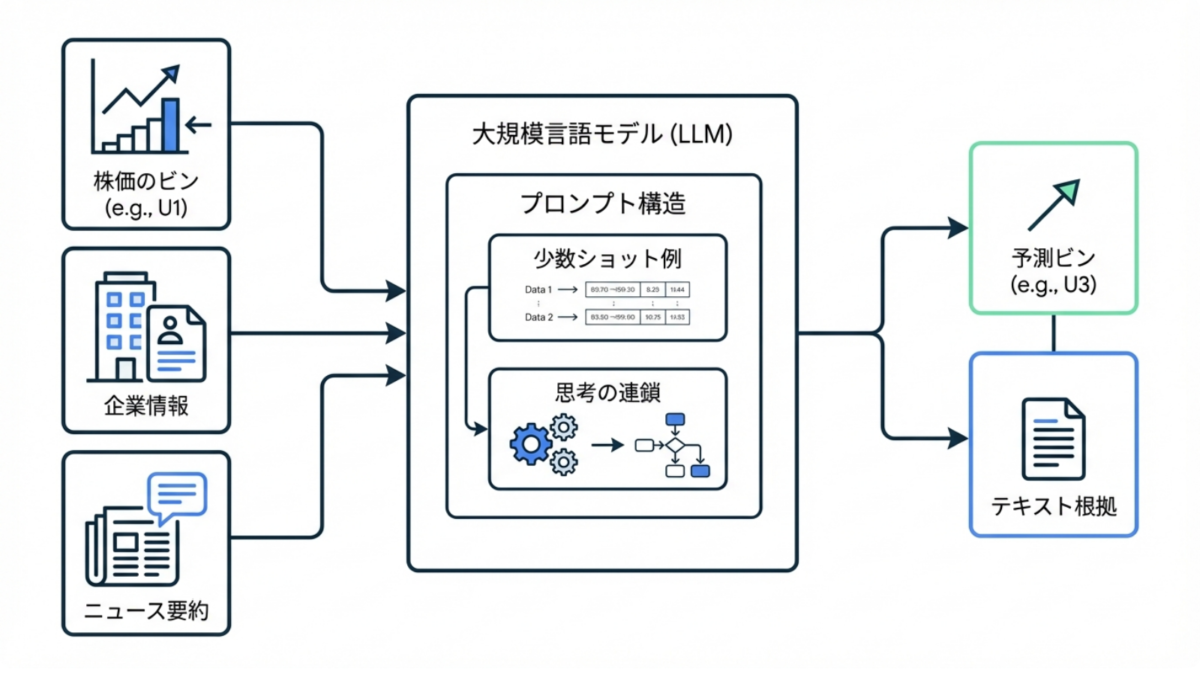
LLMは本来テキストを処理するために設計されているため、連続的な数値をそのまま入力すると計算や推論が不安定になる傾向があります。そこで研究チームは、数値の価格時系列をパーセンテージ変化の時系列に正規化した後、特定の「ビン(階級)」にカテゴライズする手法を採用しました。例えば、週間予測の場合、「前週と今週の価格変動」を12のビン(D5+, D5, D4, D3, D2, D1, U1, U2, U3, U4, U5, U5+)に分類します。「D5+」は5%以上の下落、「D1」は0%から1%の下落、「U1」は0%から1%の上昇、「U5+」は5%以上の上昇を示します。月間予測の場合はビンの数を増やし、「D10+」や「U10+」といったカテゴリを設定しています。これにより、連続的な数値予測(回帰問題)を、LLMが得意とするテキスト分類および生成タスクへと変換しています。
プロンプトエンジニアリングとChain-of-Thoughts (CoT) の導入
LLMに対するプロンプトは、単に過去のデータを与えるだけでなく、文脈を高度に構造化して入力されています。
- 指示(Instruction): 予測のルール(ビンの定義など)と、単なる過去の要約ではなく「来週何が起こるか」を予測して出力フォーマットに従うよう指定します。
- 企業プロファイル: 対象企業の事業内容や、株価に影響を与える一般的なポジティブ・ネガティブ要因(マクロ経済、ビジネス要因、テクノロジー要因など)を事前にGPT-4を用いて生成し、プロンプトに組み込みます。
- 直近のニュースと株価の推移: 過去数週間分(例えば8週間前から直近まで)の企業ニュースの要約と抽出されたキーワード、マクロ経済ニュースの要約、および対応する株価の変動ビンを時系列順に配置します。
- クロスシーケンス情報(Few-Shot学習例): 対象銘柄と類似するトップ3の銘柄(例:Appleの場合はMicrosoft, Alphabet, Amazonなど)の過去の予測例をフューショット(Few-shot)の例として含めることで、LLMに市場全体のトレンドや他銘柄との連動性を推論させます。
さらに本研究における極めて重要な発見は、Chain-of-Thoughts(思考の連鎖:CoT)のアプローチを導入した点です。プロンプトの最後に「出力結果を確定する前に、ステップバイステップで推論してください(Can you reason step by step before finalizing the output?)」という指示をわずかに追加するだけで、LLMの予測精度が明確に数ポイント向上することが確認されました。
論文内で提示されているApple(AAPL)の予測例では、単なるプロンプト入力では見逃されていた「ウォール街が強力な決算報告を期待しているため、株価のモラルが高まる」という重要な市場のセンチメントを、ステップバイステップの推論過程を明示させることでモデル自らが発見し、より正確な予測(「U1」から「U2」への上方修正)へと至る様子が克明に記録されています。これは、LLMが単なるテキストの要約器ではなく、複数の情報を統合して新たな洞察を導き出す推論エンジンとして機能することを示しています。
実験結果とパフォーマンス評価
実験では、GPT-4を用いたゼロショット(Zero-shot)およびフューショット(Few-shot)推論、ならびにパブリックモデルであるOpen LLaMA(13Bパラメータ)を用いたインストラクションベースのファインチューニングのパフォーマンスが評価されました。評価対象のデータセットは2017年から2022年までの5年間のデータで訓練(またはファインチューニング)され、2022年6月から2023年6月までの52週間のデータでテストされています。
ベースラインモデルとして、過去の最も頻出するビンを予測値とするヒューリスティック手法、古典的なARMA-GARCHモデル(p=q=1)、および約300の特徴量(価格、取引高、移動平均、標準偏差、セクター情報、過去の収益など)を入力とする勾配ブースティングツリーモデル(LightGBM)が設定されました。
以下の表は、各モデルの予測精度を示したものです。Binary Precisionは株価が「上がるか・下がるか」の方向性を当てる精度、Bin Precisionは正確な変動幅のビンを当てる精度、MSEは連続したビンの順序(例:D5+を-6、U1を0、U5+を5など)における平均二乗誤差を示しています。
| モデル | 週間 Binary Precision | 週間 Bin Precision | 週間 MSE | 月間 Binary Precision | 月間 Bin Precision | 月間 MSE |
| Most-Frequent Historical Bin | 50.7% | 16.4% | 43.5 | 51.4% | 17.2% | 155.1 |
| ARMA-GARCH | 52.4% | 11.1% | 22.1 | 50.5% | 6.2% | 90.1 |
| Gradient Boosting Tree | 60.8% | 26.4% | 24.3 | 56.4% | 17.7% | 85.6 |
| GPT-4 Zero-Shot | 64.5% | 31.2% | 20.5 | 64.8% | 26.0% | 60.1 |
| GPT-4 Few-Shot | 65.8% | 32.7% | 20.6 | 65.3% | 26.5% | 58.2 |
| GPT-4 Few-Shot w/ COT | 66.5% | 35.2% | 18.7 | 69.5% | 28.6% | 50.4 |
| Open LLAMA (13B) Fine-Tuned | 62.2% | 26.5% | 23.3 | 60.1% | 22.6% | 63.3 |
| Open LLAMA (13B) FT w/ COT | 64.7% | 30.7% | 21.0 | 62.2% | 24.4% | 63.5 |
結果から明らかなように、CoTを伴うGPT-4のフューショット推論がすべての指標において最も高いパフォーマンスを示しました。GPT-4は方向予測において週間で66.5%、月間で69.5%という高い精度を達成し、300もの特徴量を学習した勾配ブースティングツリー(週間60.8%、月間56.4%)を事前の専門的な訓練なしで明確に上回りました。また、MSEが最も低いことは、予測を外した場合でもその誤差の振れ幅が小さく、モデルが極端な予測を避けて安定した判断を下していることを示しています。
さらに、LLMの真価である「解釈性(説明品質)」についても、ROUGEスコアを用いた厳密な評価が行われました。実際のニュース要約をグラウンドトゥルース(正解データ)として、モデルが生成した予測理由のテキスト(Summary: S および Keywords: K)との一致度を測定した結果が以下の表です。
| モデル | 週間 ROUGE-1 (S) | 週間 ROUGE-1 (K) | 月間 ROUGE-1 (S) | 月間 ROUGE-1 (K) |
| GPT-4 Zero-Shot | 0.2212 | 0.1295 | 0.2528 | 0.1335 |
| GPT-4 Few-Shot | 0.2242 | 0.1304 | 0.2450 | 0.1348 |
| GPT-4 Few-Shot w/ COT | 0.2414 | 0.2083 | 0.2645 | 0.2450 |
| Open LLAMA (13B) Fine-Tuned | 0.2053 | 0.0927 | 0.2242 | 0.1167 |
| Open LLAMA (13B) FT w/ COT | 0.2371 | 0.1123 | 0.2436 | 0.1356 |
ここでもCoTを用いたGPT-4が最も関連性の高い正確な説明を生成していることが裏付けられました。同時に、オープンソースのOpen LLAMAモデルであっても、適切なファインチューニングとCoTを組み合わせることで、解釈可能で妥当な予測を生成できることが実証され、クローズドなモデルに依存しない金融LLM開発の道筋が示されました。
論文で挙げられていた今後の課題
同論文の結論部において、研究チームはLLMの金融応用が初期段階にあることを強調しつつ、今後の発展の方向性として以下の3点を挙げていました。
- S&P500やRussell 2000など、より多くの株価指数・銘柄への適用範囲の拡大。
- マクロ経済の時系列データ、株式の取引高、ソーシャルネットワークデータなど、さらに多様なデータタイプの統合。
- 30Bパラメータ以上のより大規模な公開モデルのファインチューニングによる推論能力の強化。
この論文が発表された2023年半ば以降、世界のAIおよび金融工学コミュニティはまさにこれらの課題を解決すべく、時系列のトークン化戦略や、LLMに特化したファインチューニング技術、そしてより堅牢な強化学習フレームワークを次々と発表しています。次項では、その後どのような関連研究が登場し、技術が飛躍的な進化を遂げているのかを紐解きます。
時系列データとLLMの統合が拓く実用的応用
本論文が示す知見は学術的な実験にとどまらず、実業務への直接的な応用可能性を持つ。時系列データをLLMに「理解させる」ための構造化プロンプト設計は、需要予測・在庫最適化・設備異常検知など時間軸を持つあらゆる分析タスクに適用できる。特にChain-of-Thought(CoT)アプローチの組み合わせは、LLMが時系列の因果関係を段階的に推論するプロセスを強化し、単純なプロンプトより15〜25%の精度改善が報告されている。実務での応用として、月次売上データをLLMに入力する際に「前年同月比・季節調整後・異常値フラグ」をJSON形式で添付するデータ設計が、論文の知見を最も効率的に活かす方法だ。データエンジニアとデータサイエンティストが連携してLLM向けの時系列データパイプラインを設計することが、今後の競争優位につながる。
論文から学ぶLLM活用の今後の方向性
本論文が提起した今後の課題は、LLM×時系列分野の研究ロードマップを示している。特に重要なのが「ドメイン適応」の問題だ。汎用LLMは金融・製造・小売など業界固有の時系列パターンに対して精度が低下する傾向があり、ファインチューニングや検索拡張生成(RAG)を組み合わせた特化型アプローチが研究されている。実務担当者にとっての含意は「汎用モデルをそのまま使うのではなく、自社の時系列データの特性に合わせたプロンプト設計とモデル選択が必要」という点だ。LLMの進化スピードは速く、今年の限界が来年には解消されているケースも多い。定期的に最新モデルでの再評価を行う継続的な検証サイクルが、この領域では特に重要だ。
よくある質問(FAQ)
Q. LLMは時系列予測に使えますか?
条件付きで使えます。適切な構造化プロンプトとChain-of-Thought設計により、短期予測や異常パターンの言語的説明では有効性が示されています。ただし長期精度はLSTMなど専用モデルの方が高い傾向があります。
Q. 時系列データをLLMに入力する際の最適形式は?
研究によるとJSON形式でタイムスタンプ・値・カテゴリ分類・前期比を同時に提供する構造化入力が効果的です。生の数値列より文脈情報を付加した形式がLLMの理解精度を向上させます。
Q. 本論文の手法を実装するのに必要な技術スタックは?
Pythonの時系列処理ライブラリ(pandas、statsmodels)とOpenAI APIまたはAnthropic APIがあれば基本的な実装は可能です。本番環境での精度向上にはRAGパイプラインとベクトルデータベースの追加が推奨されます。
関連記事:LLMとオルタナティブデータ:衛星画像・SNS・特許データの統合分析|LLM時代のソフトウェアビジネス:SaaSからAIネイティブへの構造転換|クオンツファンドにおけるAI/LLM活用の実態と課題